
SayPlan= Grounding Large Language Models using 3D Scene Graphs for Scalable Robot Task Planning
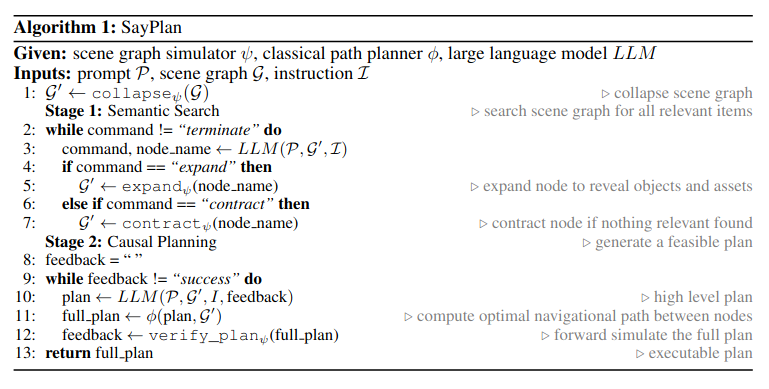
主要的思想都在上面这个伪代码里,通过只展开部分场景图(严格层级结构),来控制输入llm的场景图大小。
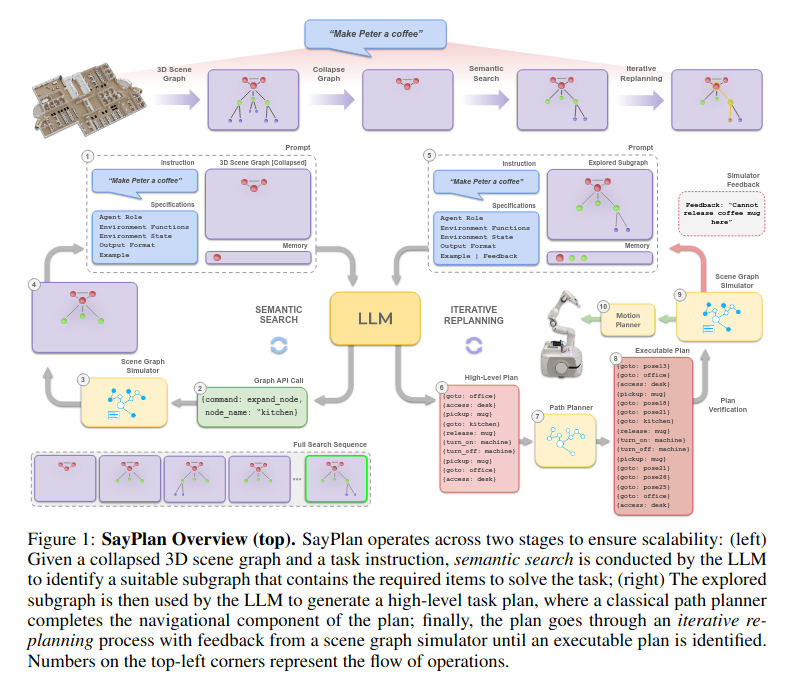
A scalable approach to ground LLM-based task planners across environments spanning multiple rooms and floors
Scene Graph 通过networkx (python package)表示
Three key innovations:
- 通过
Collapsed 3DSG来在少数根节点上寻找task-relevant子图(后续通过展开子图进行进一步的搜寻),提高了scalability(避免过于复杂的整体场景图超过LLM的token限制) - 环境中任务计划的horizon会随着给定任务的复杂性而增长,LLM会倾向于产生幻觉或者不可行的动作序列。所以通过成熟的path planner such as Dijkstra来连接high-level nodes。
- An iterative replanning pipeline in order to correct for any unexecutable actions
- Missing to open the fridge before putting something into it
因此,避免由于环境本身的物理限制和谓词的矛盾,幻觉或不一致而导致的计划失败。
- Missing to open the fridge before putting something into it
Insight
- 每一次场景节点的展开与否,该节点是否是任务关注的节点都是由LLM决定的,这一点和我的想法一致。等于是将LLM作为一个检查器一层层遍历查找任务的兴趣点。
Scene Graph Simulator作为任务是否可行的验证器。
SayPlan= Grounding Large Language Models using 3D Scene Graphs for Scalable Robot Task Planning


